Stumbling around the decision boundary
Finlay Maguire
root@finlaymagui.re
Getting into Machine Learning
- What is my background
- How I got into ML
- Overview of ways I've used ML
- What I wish I had known earlier
Background
- High school "computing" and maths
- Bioscience Undergraduate: insigificant courses and research project
- Finishing Bioinformatics PhD looking
- So no significant formal training in ML, maths or computer science
Textbooks

- Christopher Bishop's "Pattern Recognition and Machine Learning"
- Kevin Murphy's "Machine Learning: A Probabilistic Perspective"
- Gilbert Strang's "Linear Algebra and Its Applications"
Practice

- Provided Dataset
- Evaluation Metric
- Public-Private scoreboards
- Top N winners methods and code are released publically (on Kaggle's No Free Hunch Blog)
Warning
 Kaggle can and will eat your time
Kaggle can and will eat your time
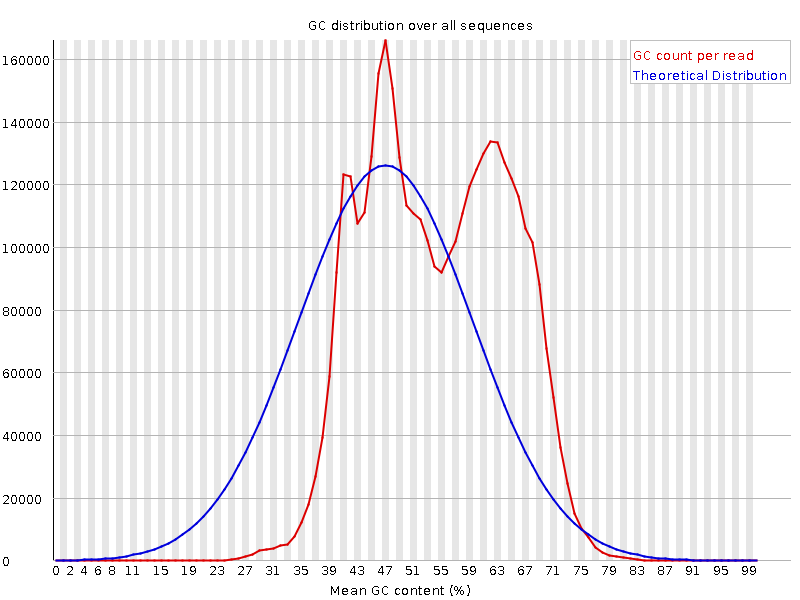 Metatranscriptome GC %
Metatranscriptome GC %
- 400M 150bp PE reads (159GB)
- K-means clustering
- Fit GMM using Expectation-Maximisation
- Python (SKLearn) still hadn't finished PARSING input after 48 hours
- C++ (MLPACK/ARMADILLO): 12 hours (6GB of memory) single threaded
- Lesson: use the right tool for the job (Python: Scikit-Learn, R: Caret, Java: Weka, C++: MLPACK etc)
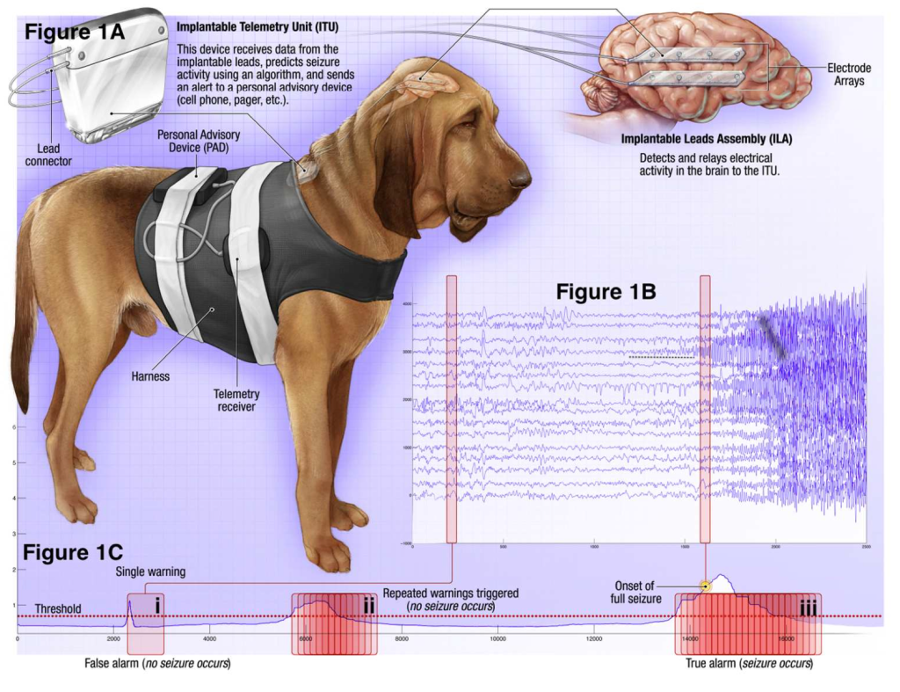 American Epilepsy Society Seizure Prediction Challenge
American Epilepsy Society Seizure Prediction Challenge
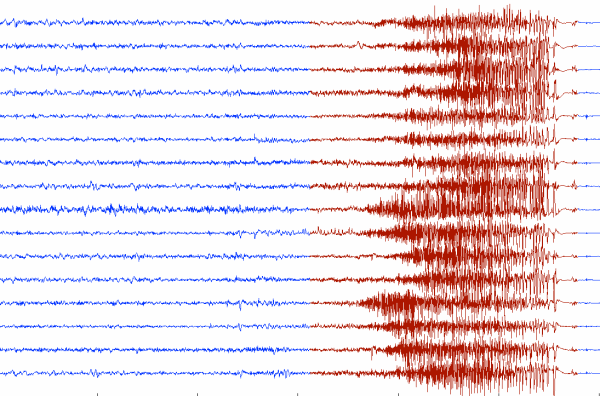 iEEGs
iEEGs
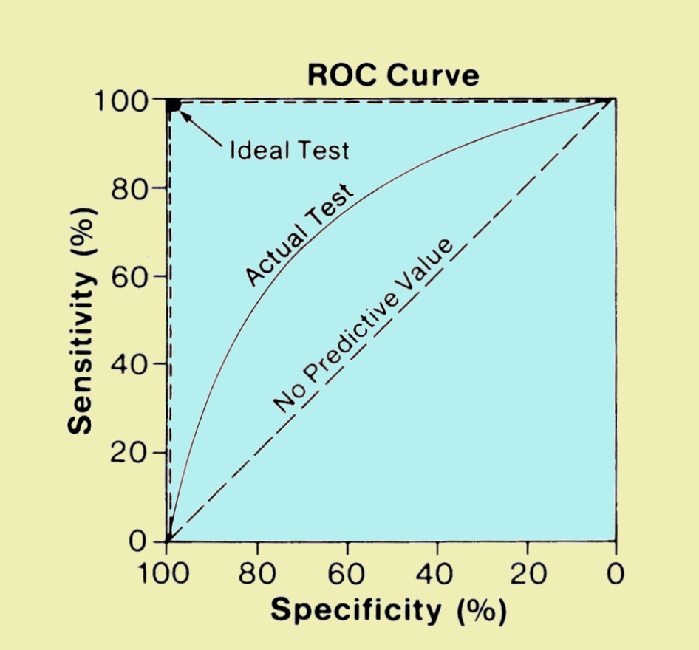 true positives (sensitivity) vs false negatives (decreased specificity) (source)
true positives (sensitivity) vs false negatives (decreased specificity) (source)
Data processing and feature extraction
- Data preprocessing: downsampling, cleaning
- Channel correlations: independent component analysis, common spatial patterns, MVARs
- Approximately 850 different features
- Recursive Feature Elimination
Machine learning
- Random forests
- Support Vector Machines
- Logistic Regression
- Adaboost
- Ensembles!
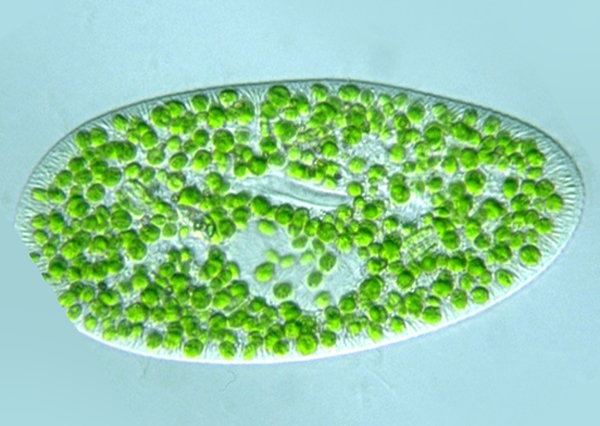 Paramecium bursaria with Micractinium reisseri endosymbiont
Paramecium bursaria with Micractinium reisseri endosymbiont
- Metatranscriptome origin classification
- Goal: classify transcripts into origin species
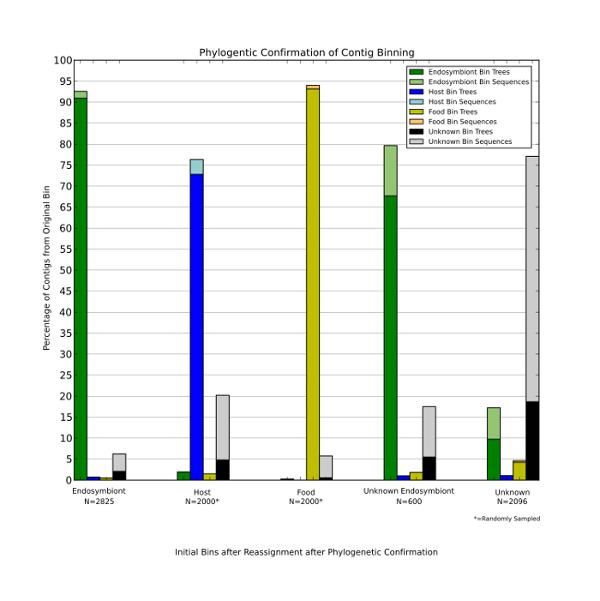 Phylogenetics vs top BLAST hits
Phylogenetics vs top BLAST hits
- Features: Phylogenetic tree and sequence features (GC, trinucleotide)
- SVM/RVM
- F1 Score nearly as good as manual (ad hoc self-consistency...)
 Image classification of plankton
Image classification of plankton
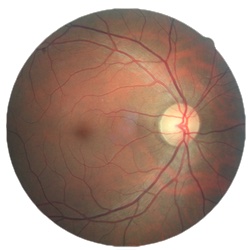
- Diabetic retinopathy detection
- Two eyes, 5 ratings for each eye
- Same ML approach as NeuKrill-Net
- Difficult cost function (quadratic negative kappa)
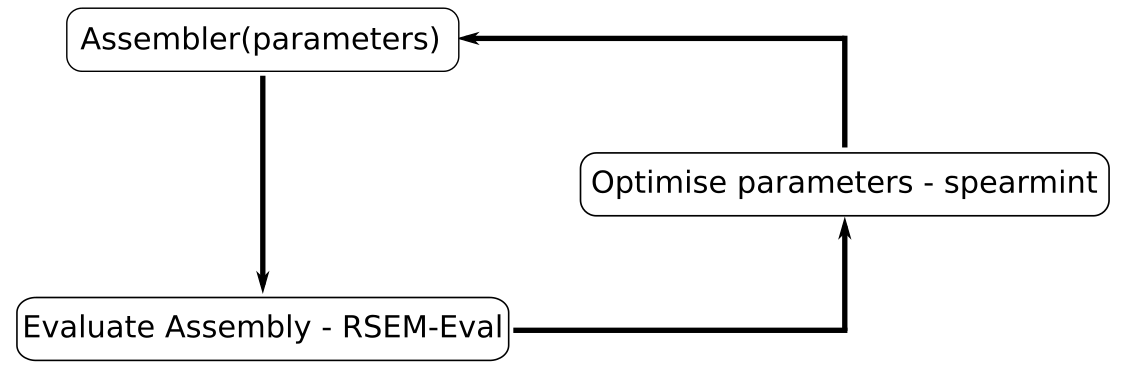
- de novo assembly parameter optimisation (k-mer size, minimum coverage, normalisation)
- Bayesian optimisation of assembly likelihood
- Spearmint experimentation evaluated using RSEM-eval
- Key challenges i.e. representative subset, generalising for assemblers
- Short-form spoken word recommender system
- Goal: Recommender system for audioclips
- Hare brained startup
- Audiotranscription and metadata (project Gutenberg)
- Very much a work in progress
- RNN and LSTM are really cool
Things I wish I had known or understood earlier!
Plot everything
- Exploratory data analysis
- Plot density, scatter, structure of data
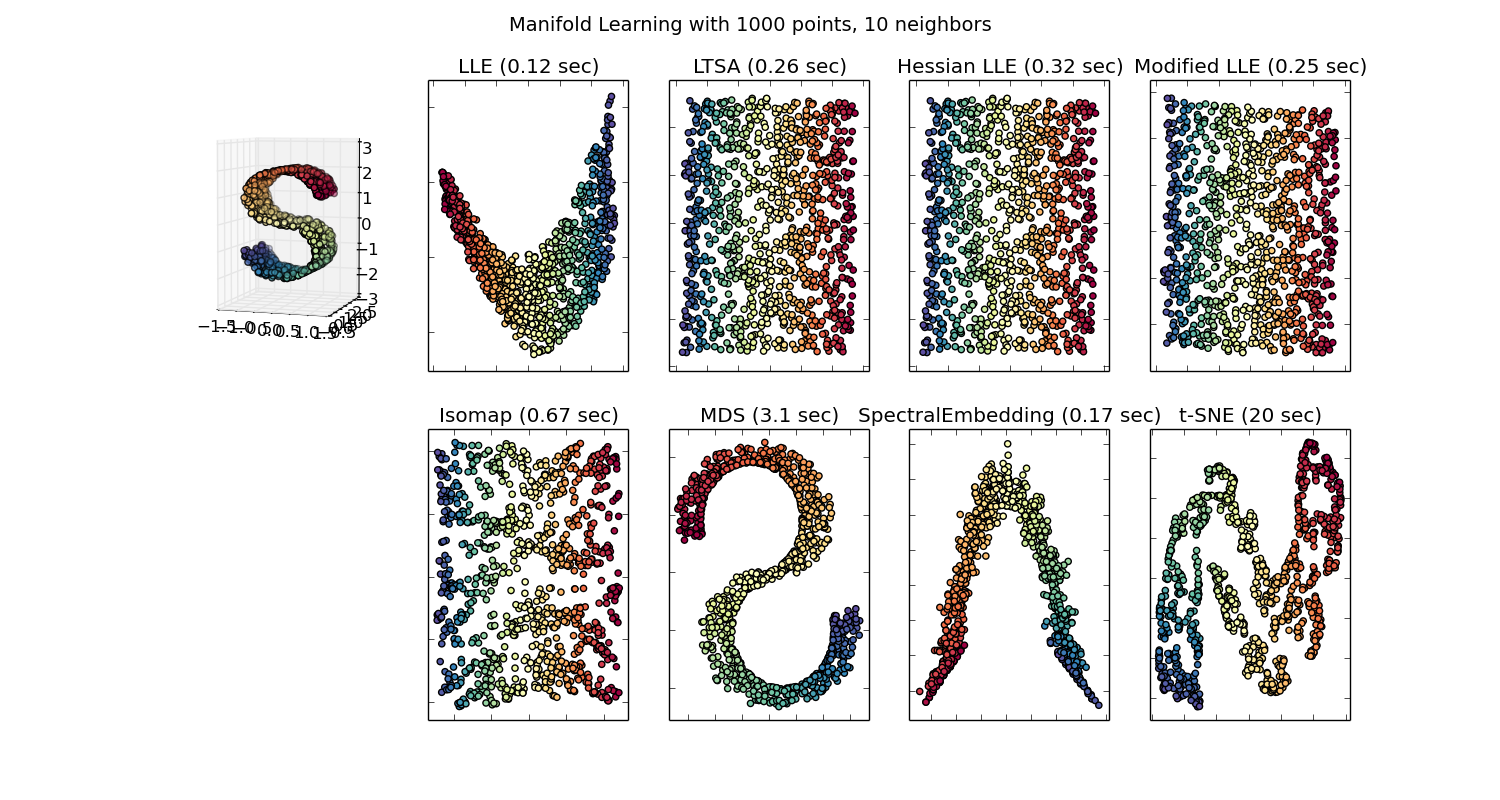
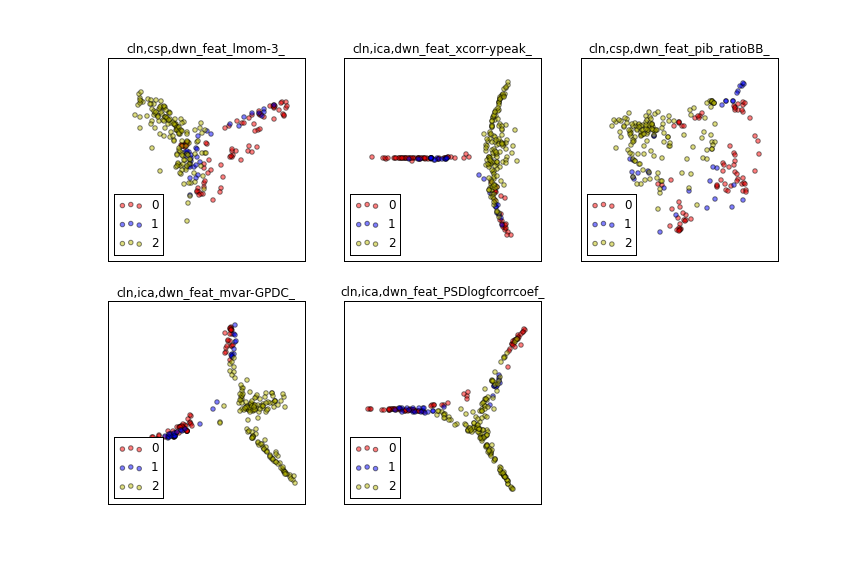 t-SNE of EEG features
t-SNE of EEG features
No Free Lunch
- "any two [...] algorithms are equivalent when their performance is averaged across all possible problems"
- No universally best optimiser, classifier, or metric
- Wolpert and McCreedy proofs
- Real world not so nicely random
ML = Method + Evaluation + Optimisation
- The ML algorithm (e.g. KNN, SVM, RF etc) is only part of the problem
- Important to be aware of evaluation (e.g. sum of squares distance, error)
- and optimisation method (e.g. gradient descent, expectation-maximisation)
- Can make a big difference to performance (and run time)
- Ties into NFL theory
Curse of dimensionality
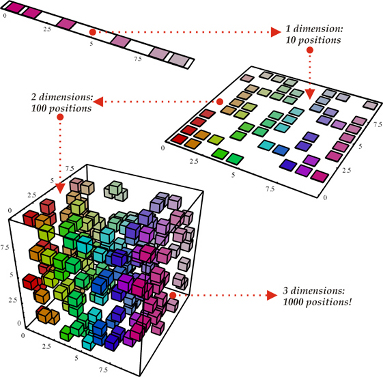 from Bengio's homepage
from Bengio's homepage
- Intuitions will fail in high dimensions
Highly iterative process
- Most of the work is the boring stuff
- Data exploration
- Data gathering
- Data cleaning
- More data can beat smarter algorithms (but not always)
- Worth taking time setting up tools and data
- UNIT TESTS
- Literate programming e.g. Rmd, Jupyter
- Version control e.g. git
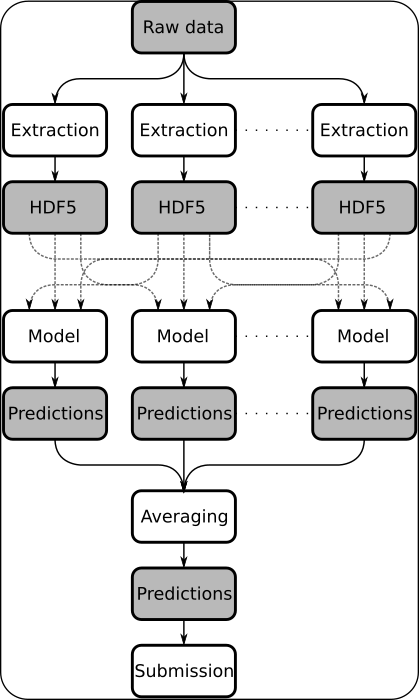
If in doubt combine models!
- Bagging (average estimators trained on random subsets of data)
- Merging (model averaging)
- Stacking (feed estimators into other estimators)
- Boosting (iteratively train estimators on data that previous models misclassify)
- Machine learning can be used to do cool things
- It is not as opaque as it appears
- Optimisation and Evaluation is as important as ML algorithm
- Highly iterative process
- Use version control and literate programming to save yourself a lot of difficulty