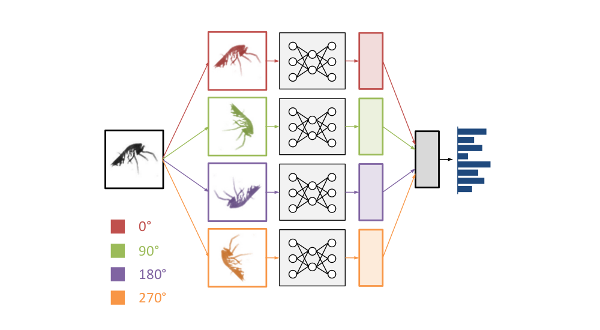
Casting a Deep Net: Classifying Plankton from Images
Finlay Maguire
root@finlaymagui.re

- 90 days (December 15th 2014 - March 16th 2015)
- Sponsored by Booz Allen Hamilton
- Run by Kaggle
- Hatfield Marine Science Center
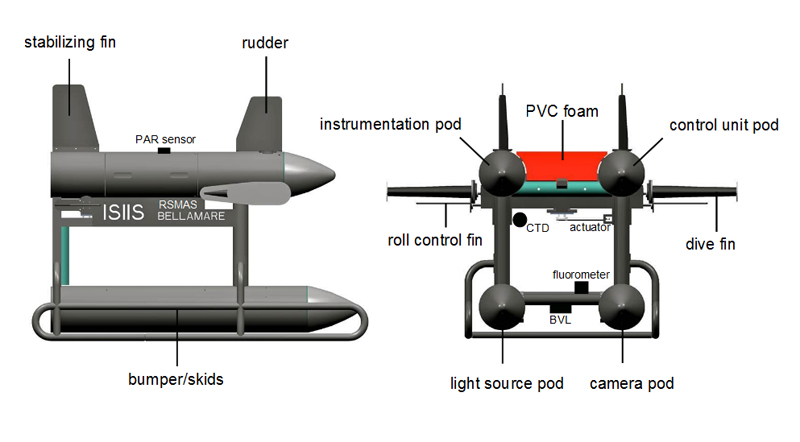
- In Situ Ichthyoplankton Imaging System
- 5 million shadowgraph images (4-5TB) a day
- Automatically segmented
- Manual analysis infeasible
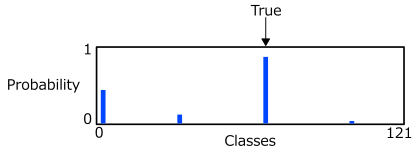
- Reliable automated identification of plankton
- 121 provided labels
- Generate probability distribution for each image across labels

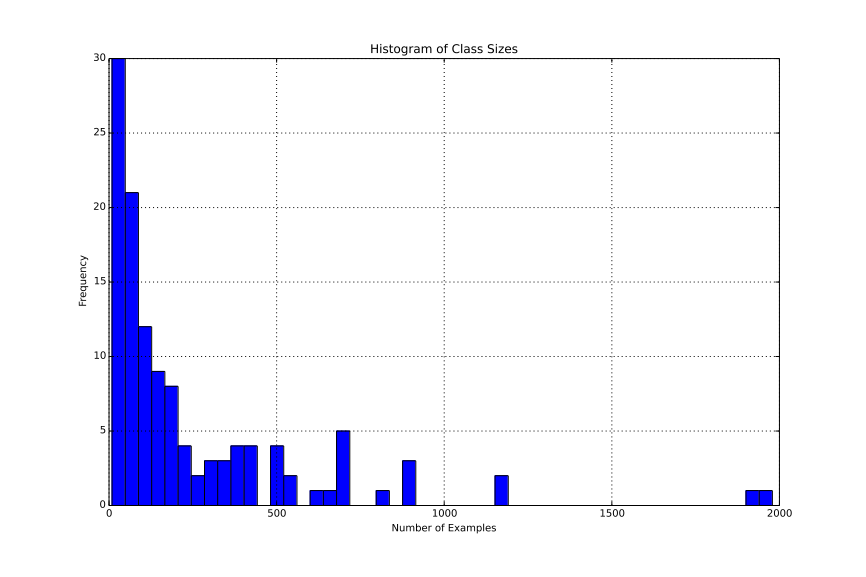
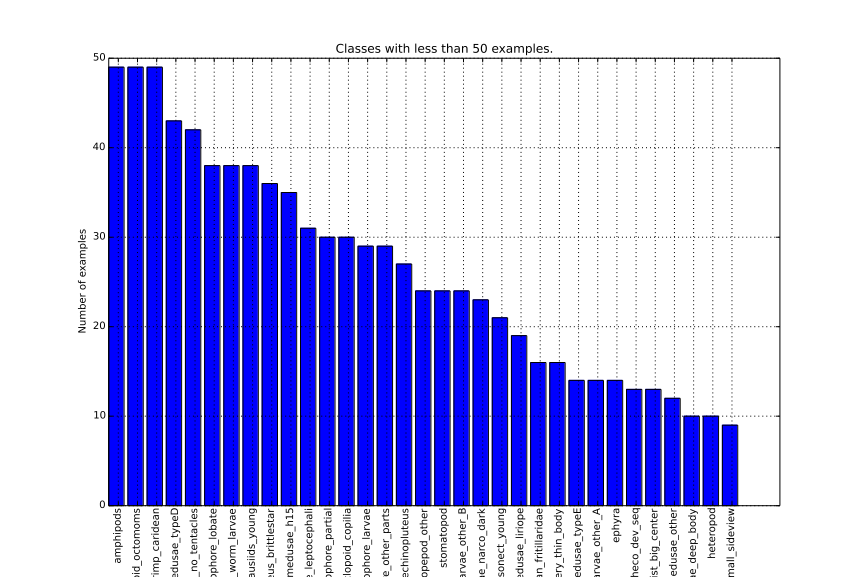

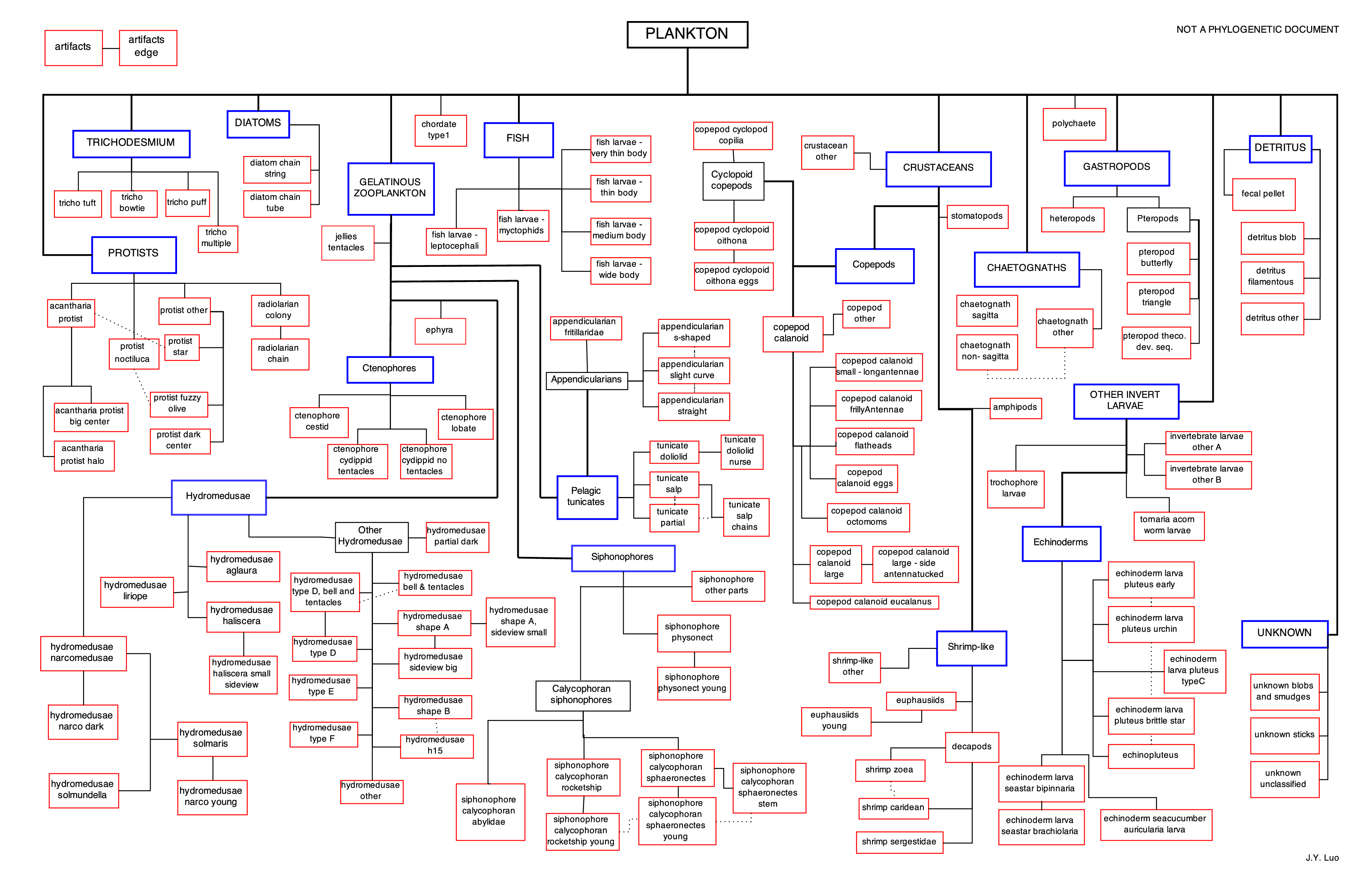
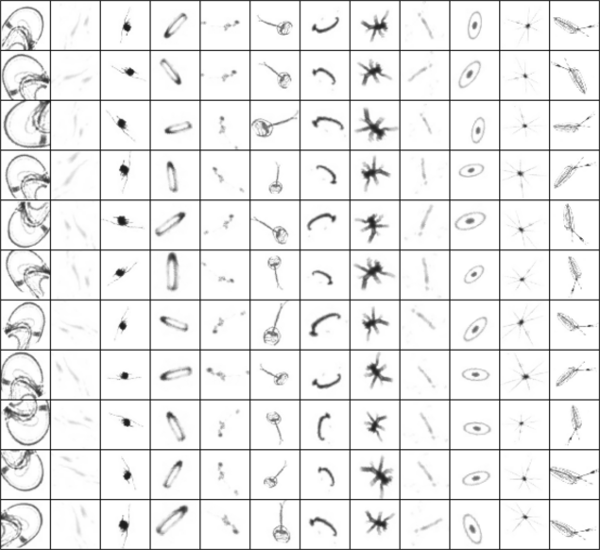
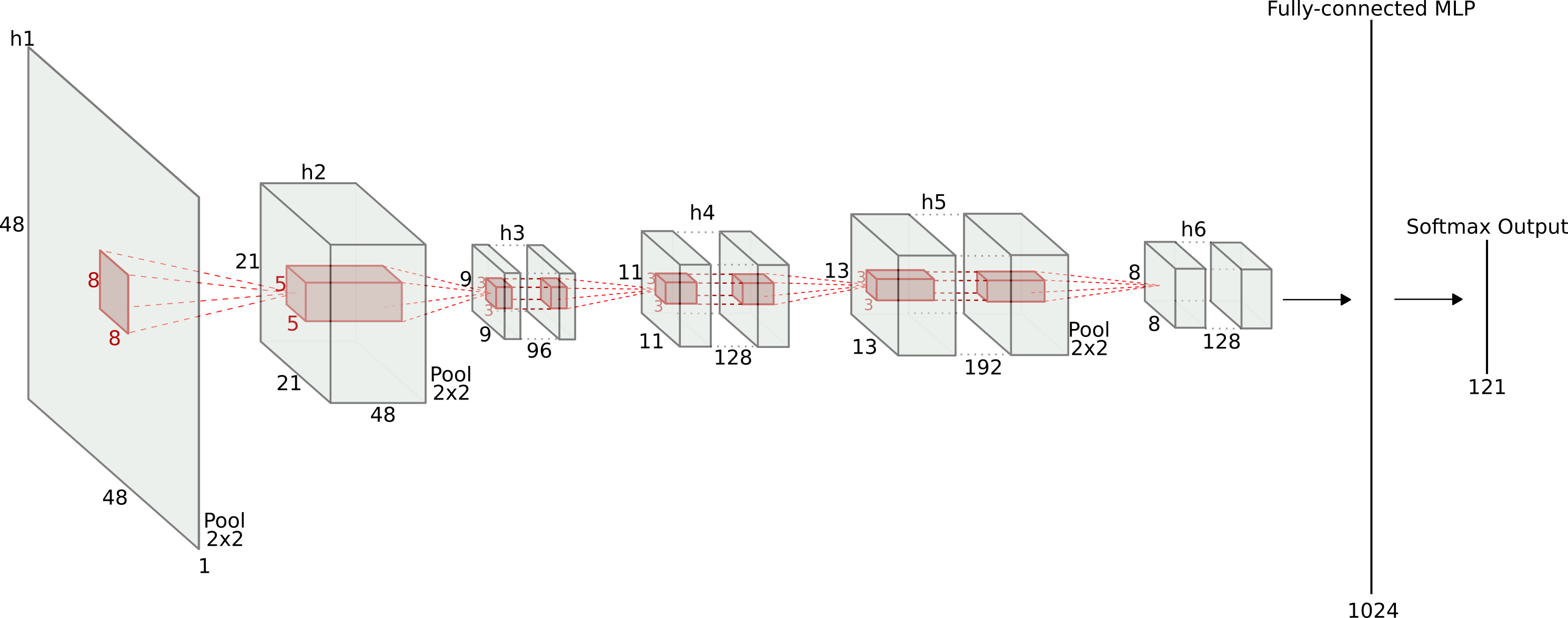
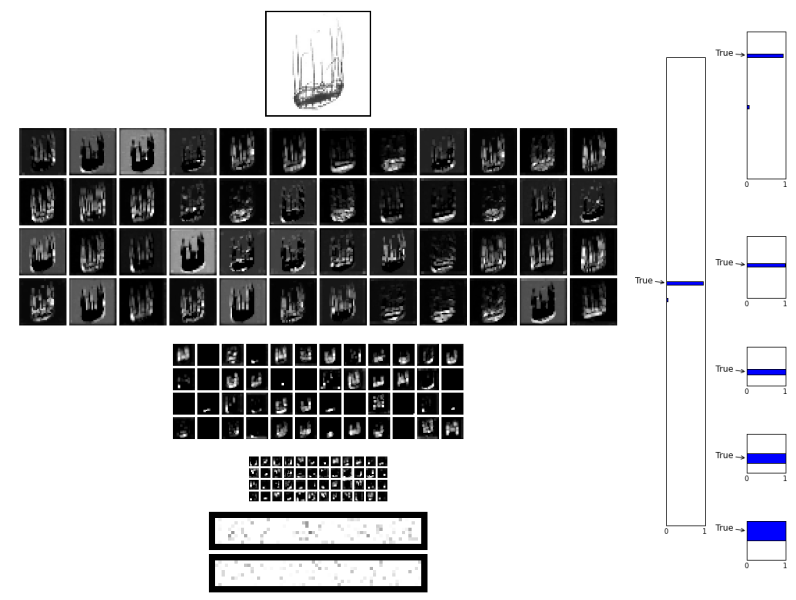
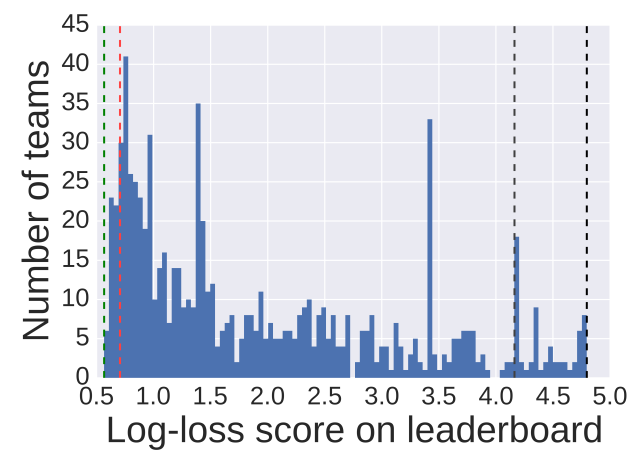
- 57/1,054 teams (5.4%)
- Our LL and PPV = 0.704, 74.38%
- Winner LL and PPV = 0.565, 81.52%
- Very similar methodologies